站长在查看网站日志,分析搜索引擎蜘蛛抓取过程中,经常会遇到一些莫名其妙的IP,这些怪异的行为也让很多站长出现困惑。比如你还没有发布网站信息,但日志中就显示在发布之前已经抓取访问过,再比如一些IP是无法查询到准确来路等等。
而出现这种情况,首先需要了解什么是真假蜘蛛。搜索引擎蜘蛛的真伪,是相对来说,通常来自搜索引擎的蜘蛛,是站长优化网站的依据,然而很多采集程序,站长工具的抓取是模仿蜘蛛的抓取。那如何判断网站搜索引擎蜘蛛的真假呢?
在查看网站常用日志的工具中我们有提到金花站长工具,使用此工具可以将真假蜘蛛分辨出来,但是无法从根本上发现它为什么是假蜘蛛。在Windows操作系统中,用Dos窗口tracert可以准确查看。
打开Dos窗口,输入cmd,输入“tracert + IP”,以网站日志内IP为例:

从查询结果可以得知,如果显示cralw.baidu.com,且出现baidusipider, 类似于(baiduspider-123-125-71-48.crawl.baidu.com [123.125.71.48]),则说明这个IP是真实的百度蜘蛛。出现crawl.sogou.com则表示是搜狗蜘蛛。
经常查看网站日志的站长可以观察,基本上从命令返回值,可以大概知道在123.125.71.*,220.181.108.* ,这两个IP段属于百度蜘蛛的IP。因此,在查看网站日志,可以很快的分辨出哪些是百度蜘蛛抓取的时间,哪些是其他搜索引擎抓取的时间。常见的各搜索引擎蜘蛛IP段如下:
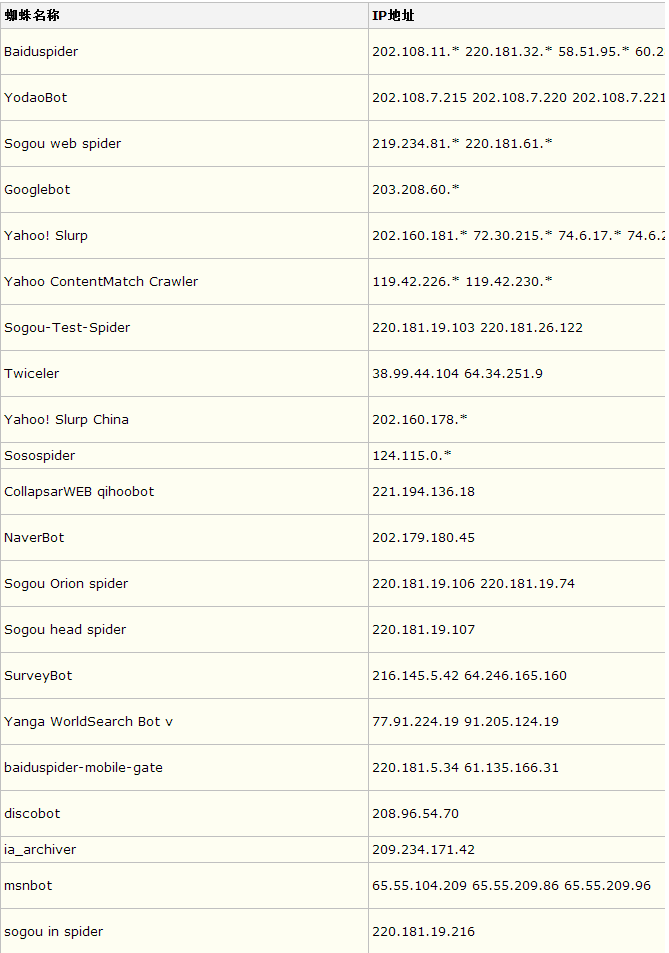
一般而言,虚假蜘蛛不会出现太多,当然,如果遇上网站被虚拟IP攻击,或者被采集,那么如何禁止呢?常见的方法是可以通过百度推广后台的禁止IP工具,或者利用服务器的安全防护,可以禁止相关的IP访问。
相关阅读:香港主机后台如何查看网站日志